
之前有做过一些大数据工程的项目,由于spark不是我的技术栈范围,所以取巧用了hive-udf编译的python脚本。想来spark是未来数据处理的趋势,所以最近开始学习pyspark,这个系列的博客将会边学边记录,可能会比较囫囵吞枣。第一篇会记录pyspark学习所需要的环境配置。
PySpark环境设置
一般的普罗大众想学习Spark,很难自己去配置好整个Spark集群和套件等相关运行环境,这样成本太高,入门难度也太大。受益于如今容器化技术(比如Docker)的发展,学习新技术的环境配置门槛被大幅降低,我们可以通过官方社群中所提供的已经预配置好的Docker镜像(Image)来模拟整个学习研究环境,我们只需要专注于想学的技术核心本身,而不用花大把精力去搞研究环境的搭建。
对于对容器化技术不了解的朋友,可以把它简单的理解为一个和本机相对隔离的环境,在这个环境里使用的工具包或者跑的程序的依赖工具也是用的这个环境里配置好的,而不用使用这个环境外的(比如主机自带的)。这样可以解决不同程序所需要的依赖的同一个package的版本不同的问题,使得耦合性很低,在不用的环境里运行不同的程序或者做不同的研究,相互不影响。就像在做开发的时候在pycharm里面每个project都需要单独配置一个虚拟环境,道理是类似的。
同样的,PySpark作为一个python中蓬勃向上的大数据工程类工具package,Docker Hub也有其对应的镜像。为了能方便在Jupyter中使用,Jupyter Docker Stacks提供了pyspark-notebook的Docker镜像。其实我也是第一次接触Jupyter Docker Stacks,我看了他们的文档,发现贼好用,相当于jupyter为了教学方面考虑,提供了一些重要技术工具的研究学习环境,开源共享在Docker Hub上面。目前提供的镜像还不是很多,比较有用的是:科学计算scipy相关的,神经网络tensorflow相关的和分布式计算pyspark相关的。
言归正传,要运行docker镜像,先需要下载一个docker,Mac电脑的可以直接通过homebrew安装(需要APP客户端的记得带--cask,不然就只能命令行操作了)。有了docker之后,cd到对应的研究文件夹下面,运行如下命令行指令可以运行jupyter-pyspark镜像。
$ docker run -it -p 9000:8888 -v $PWD:/home/jovyan jupyter/pyspark-notebook
上述指令-p 9000:8888代表将送往localhost:9000的通讯转送至Docker container的8888端口(也就是这个容器里Jupyter notebook的地址);而-v $PWD:/home/jovyan代表将本机当前文件夹挂载至Docker container内的路径/home/jovyan上。这儿9000可以改成其他的你想要的端口号,但是我不建议改成8888,因为8888是默认的jupyter notebook的端口号,你如果想用本机环境运行jupyter notebook的话,就需要在启动jupyter的时候单独指定其他的端口号防止跳到pyspark-notebook环境里去。jovyan是Jupyter Docker Stack的预设使用者名字,所以按它预设的文件夹名称,不用过多在意。如果想给这个容器定制命名为pyspark_tuto的话可以在run后面加上--name="pyspark_tuto"来实现。同时,如果之后想查看Spark UI,需要将4040端口也映射到本地,即在-p 9000:8888后面加上 -p 4040:4040(前面那个4040可以换成你想要的端口号)。
对于已经创建好的docker container如果想增加端口映射的话,可以参考这篇《Mac下 Docker 动态添加端口》。
上述运行成功的话,那么可以在Docker客户端里看到对应的容器:

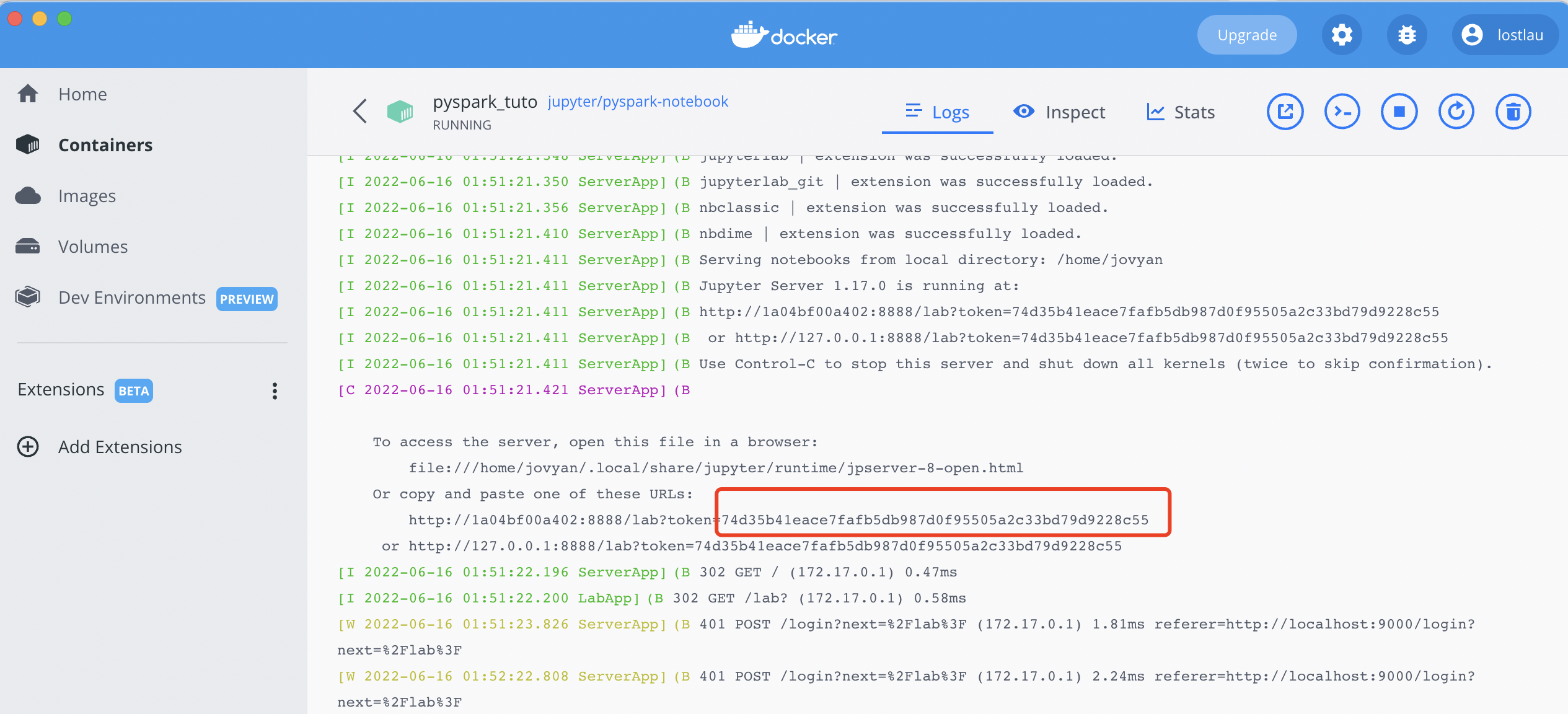
在浏览器里面输入localhost:9000就可以打开jupyter-lab的界面,如果需要token,那么可以在日志log里面找到:
PySpark基本操作
以下介绍一些基本的pyspark语法,首先载入packages依赖
import pandas as pd
import numpy as np
from pyspark.sql import SparkSession
import warnings
warnings.filterwarnings('ignore')
PySpark模块基本概念
pyspark里最核心的模块是SparkContext(简称sc),最重要的数据载体是RDD。
SparkContext是spark的主要切入点,而RDD是主要的API,所以需要通过sparkcontext来创建和操作RDD。对于不同的API,我们需要使用不同的context,比如对于streming我们需要使用StreamingContext;对于sql,使用sqlContext;对于hive,使用hiveContext。不过目前业界普遍使用DataSet和DataFrame的API逐渐成为标准API,所以在spark2.0中,引入SparkSession作为DataSet和DataFrame API的切人点。其实质也是sqlContext和hiveContext的组合(streamingContext还未实现),所以在sqlContext和hiveContext上可用的API在SparkSession上同样可以使用。SparkSession内部封装了SparkContext,计算上其实也是由SparkContext完成的。
spark = SparkSession.builder.getOrCreate()
读取数据
以下使用样例数据https://www.kaggle.com/aashita/nyt-comments
可以采用两种方法读取,一种是spark自带的read,另一种是通过转换pandas.DataFrame的方式
df = spark.read.option('header',True).option('escape','"').option('inferSchema',True).csv("archive/CommentsFeb2017.csv")
df.printSchema()
root
|-- approveDate: string (nullable = true)
|-- articleID: string (nullable = true)
|-- articleWordCount: string (nullable = true)
|-- commentBody: string (nullable = true)
|-- commentID: string (nullable = true)
|-- commentSequence: string (nullable = true)
|-- commentTitle: string (nullable = true)
|-- commentType: string (nullable = true)
|-- createDate: string (nullable = true)
|-- depth: string (nullable = true)
|-- editorsSelection: string (nullable = true)
|-- inReplyTo: double (nullable = true)
|-- newDesk: string (nullable = true)
|-- parentID: string (nullable = true)
|-- parentUserDisplayName: string (nullable = true)
|-- permID: string (nullable = true)
|-- picURL: string (nullable = true)
|-- printPage: integer (nullable = true)
|-- recommendations: integer (nullable = true)
|-- recommendedFlag: string (nullable = true)
|-- replyCount: string (nullable = true)
|-- reportAbuseFlag: string (nullable = true)
|-- sectionName: string (nullable = true)
|-- sharing: integer (nullable = true)
|-- status: string (nullable = true)
|-- timespeople: string (nullable = true)
|-- trusted: string (nullable = true)
|-- updateDate: string (nullable = true)
|-- userDisplayName: string (nullable = true)
|-- userID: double (nullable = true)
|-- userLocation: string (nullable = true)
|-- userTitle: string (nullable = true)
|-- userURL: string (nullable = true)
|-- typeOfMaterial: string (nullable = true)
import pandas as pd
import numpy as np
df_pd = pd.read_csv("archive/CommentsFeb2017.csv")
df_prime = spark.createDataFrame(df_pd.astype(str))
df_prime.printSchema()
root
|-- approveDate: string (nullable = true)
|-- articleID: string (nullable = true)
|-- articleWordCount: string (nullable = true)
|-- commentBody: string (nullable = true)
|-- commentID: string (nullable = true)
|-- commentSequence: string (nullable = true)
|-- commentTitle: string (nullable = true)
|-- commentType: string (nullable = true)
|-- createDate: string (nullable = true)
|-- depth: string (nullable = true)
|-- editorsSelection: string (nullable = true)
|-- inReplyTo: string (nullable = true)
|-- newDesk: string (nullable = true)
|-- parentID: string (nullable = true)
|-- parentUserDisplayName: string (nullable = true)
|-- permID: string (nullable = true)
|-- picURL: string (nullable = true)
|-- printPage: string (nullable = true)
|-- recommendations: string (nullable = true)
|-- recommendedFlag: string (nullable = true)
|-- replyCount: string (nullable = true)
|-- reportAbuseFlag: string (nullable = true)
|-- sectionName: string (nullable = true)
|-- sharing: string (nullable = true)
|-- status: string (nullable = true)
|-- timespeople: string (nullable = true)
|-- trusted: string (nullable = true)
|-- updateDate: string (nullable = true)
|-- userDisplayName: string (nullable = true)
|-- userID: string (nullable = true)
|-- userLocation: string (nullable = true)
|-- userTitle: string (nullable = true)
|-- userURL: string (nullable = true)
|-- typeOfMaterial: string (nullable = true)
基于DataFrame操作数据
df.select(["articleID","printPage"]).limit(1).collect()
[Row(articleID='58927e0495d0e0392607e1b3', printPage=12)]
df.createOrReplaceTempView("comment")
spark.sql("select commentBody, printPage from comment limit 5").show(truncate=True,vertical=False)
+--------------------+---------+
| commentBody|printPage|
+--------------------+---------+
|ANY anti Trump pr...| 12|
|I'll not watch th...| 12|
|NFL's going to do...| 12|
|I'm continually a...| 12|
|Personally, I do ...| 12|
+--------------------+---------+
spark.sql("select commentBody, printPage from comment limit 5").toPandas()
| commentBody | printPage | |
|---|---|---|
| 0 | ANY anti Trump propaganda from Gaga and my TV ... | 12 |
| 1 | I'll not watch the SB, nor the grammys or osca... | 12 |
| 2 | NFL's going to do another "in-your-face, Ameri... | 12 |
| 3 | I'm continually amazed at the ill-placed crede... | 12 |
| 4 | Personally, I do not want to see any politics ... | 12 |